 Free = same as above, with accelerator options and new machines
Collide = same as above, with accelerator options and new machines
Sphere = flow around a sphere, with accelerator options and new machines
Free = same as above, with accelerator options and new machines
Collide = same as above, with accelerator options and new machines
Sphere = flow around a sphere, with accelerator options and new machines
This page gives SPARTA performance on several benchmark problems, run on different machines, both in serial and parallel. When the hardware supports it, results using the the accelerator options currently available in the code are also shown.
All the information is provided below to run these tests or similar tests on your own machine. This includes info on how to build SPARTA, how to launch it with the appropriate command-line arguments, and links to input and output files generated by all the benchmark tests. Note that input files and a few sample output files are also provided in the bench directory of the SPARTA distribution. See the bench/README file for details.
Free = same as above, with accelerator options and new machines
Collide = same as above, with accelerator options and new machines
Sphere = flow around a sphere, with accelerator options and new machines
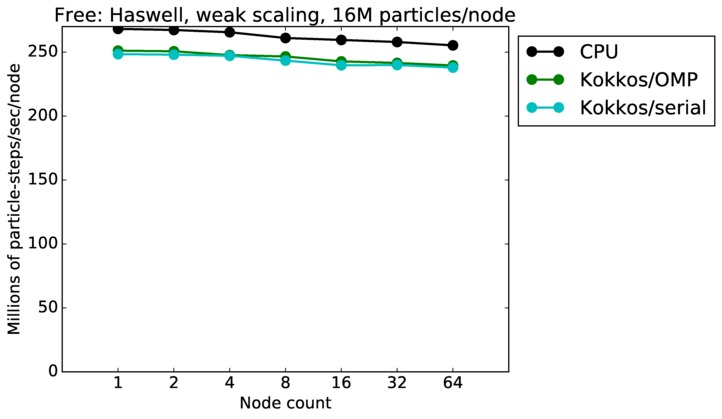
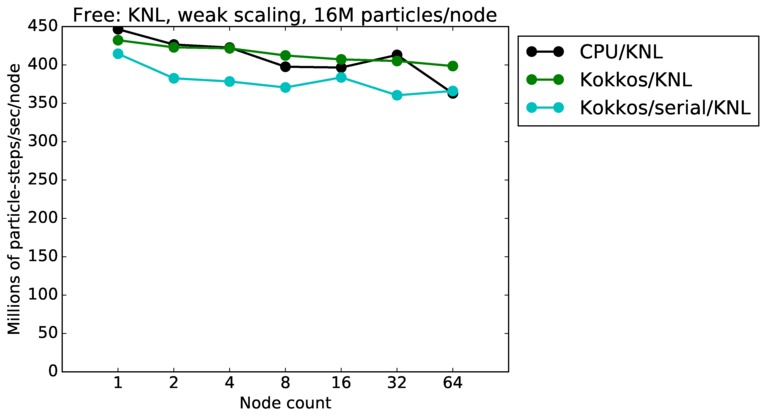
This benchmark is for particles advecting in free molecular flow (no collsions) on a regular grid overlaying a 3d closed box with reflective boundaries. The size of the grid was varied; the particle counts is always 10x the number of grid cells. Particles were initialized with a thermal temperature (no streaming velocity) so they move in random directions. Since there is very little computation to do, this is a good stress test of the communication capabilities of SPARTA and the machines it is run on.
The input script for this problem is bench/in.free in the SPARTA distribution.
This plot shows timings results in particle moves/sec/node, for runs of different sizes on varying node counts of two different machines. Problems as small as 1M grid cells (10M particles) and as large as 10B grid cells (100B particles) were run.
Chama is an Intel cluster with Infiniband described below. Each node of chama has dual 8-core Intel Sandy Bridge CPUs. These tests were run on all 16 cores of each node, i.e. with 16 MPI tasks/node. Up to 1024 nodes were used (16K MPI tasks). Mira is an IBM BG/Q machine at Argonne National Labs. It has 16 cores per node. These tests were run with 4 MPI tasks/core, for a total of 64 MPI tasks/node. Up to 8K nodes were used (512K MPI tasks).
The plot shows that a Chama node is about 2x faster than a BG/Q node.
Each individual curve in the plot is a strong scaling test, where the same size problem is run on more and more nodes. Perfect scalability would be a horizontal line. The curves show some initial super-linear speed-up as the particle count/node decreased, due to cache effects, then a slow-down as more nodes are added due to too-few particles/node and increased communication costs.
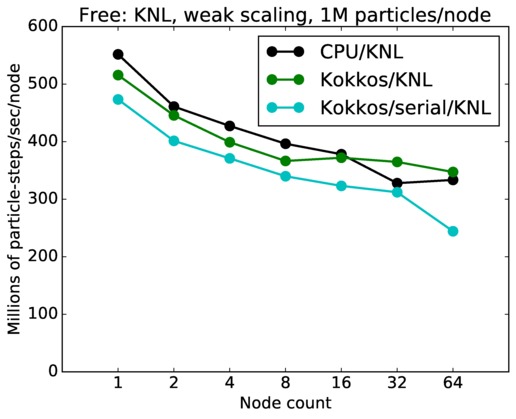
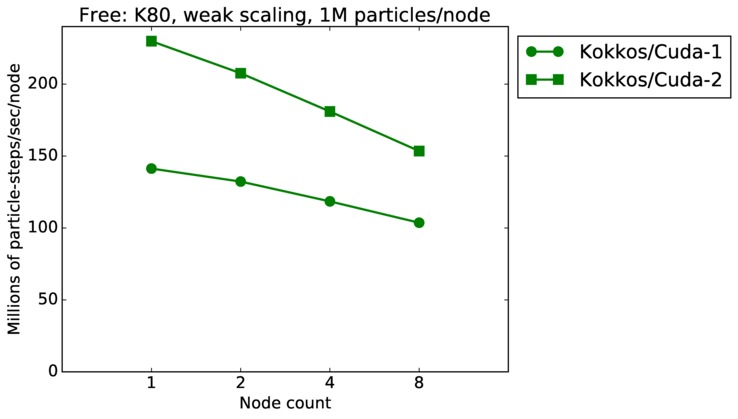
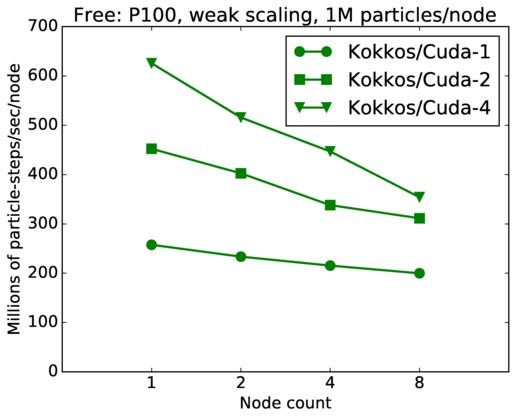
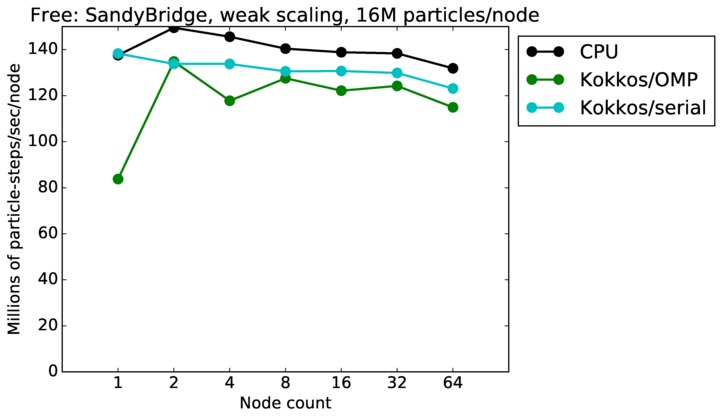
Jumping from curve-to-curve as node count increases is a weak scaling test, since the problem size is increasing with node count. Again a horizontal line would represent perfect weak scaling.
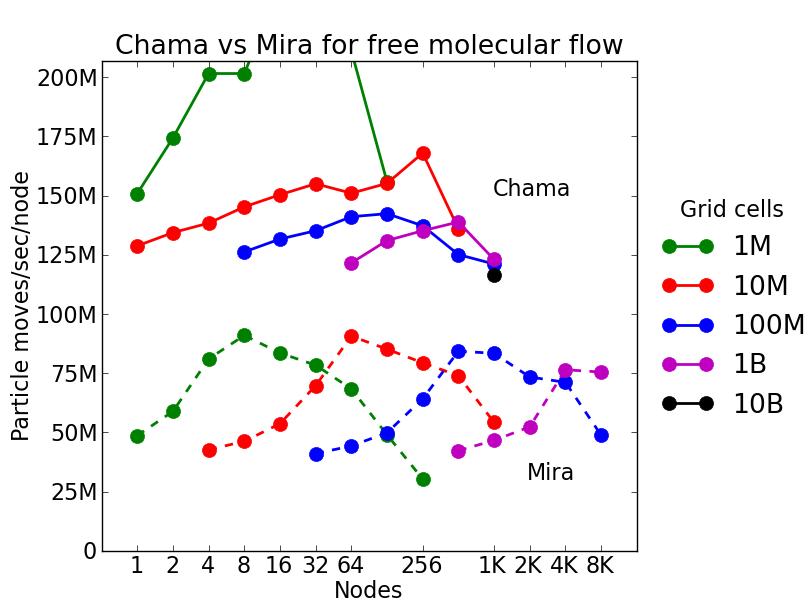
Click on the image to see a larger version.
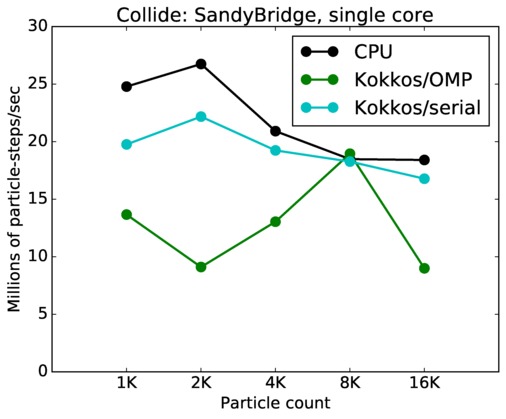
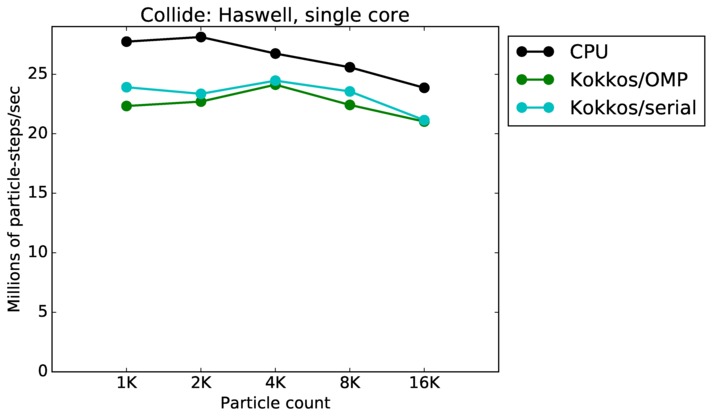
This benchmark is for particles undergoing collisional flow. Everything about the problem is the same as the free molecular flow problem described above, except that collisions were enabled, which requires extra computation, as well as particle sorting each timestep to identify particles in the same grid cell.
The input script for this problem is bench/in.collide in the SPARTA distribution.
As above, this plot shows timings results in particle moves/sec/node, for runs of different sizes on varying node counts. Data for the same two machines is shown: chama (Intel cluster with Ifiniband at Sandia) and mira (IBM BG/Q at ANL). Comparing these timings to the free molecule flow plot in the previous section shows the cost of collisions (and sorting) slows down the performance by a factor of about 2.5x. Cache effects (super-linear speed-up) are smaller due to the increased computational costs.
For collisional flow, problems as small as 1M grid cells (10M particles) and as large as 1B grid cells (10B particles) were run.
The discussion above regarding strong and weak scaling also applies to this plot. For any curve, a horizontal line would represent perfect weak scaling.
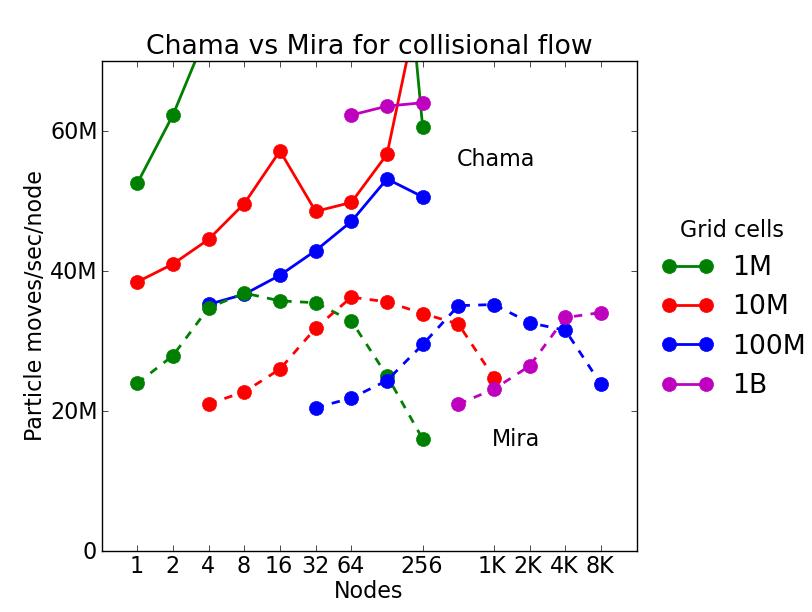
Click on the image to see a larger version.
As described above, this benchmark is for particles advecting in free molecular flow (no collisions) on a regular grid overlaying a 3d closed box with reflective boundaries. The size of the grid was varied; the particle counts is always 10x the number of grid cells. Particles were initialized with a thermal temperature (no streaming velocity) so they move in random directions. Since there is very little computation to do, this is a good stress test of the communication capabilities of SPARTA and the machines it is run on.
Additional packages needed for this benchmark: none
Comments:
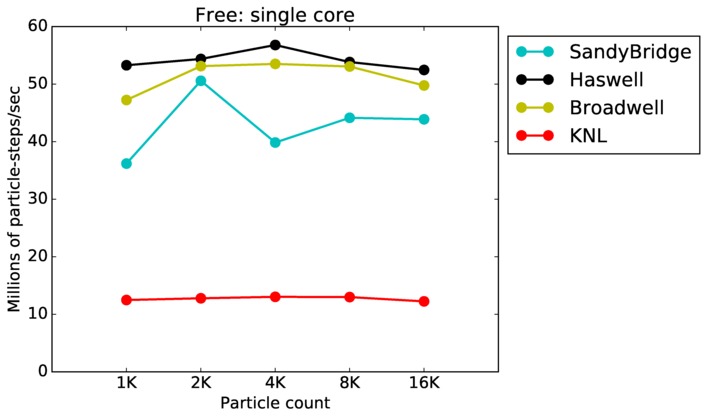
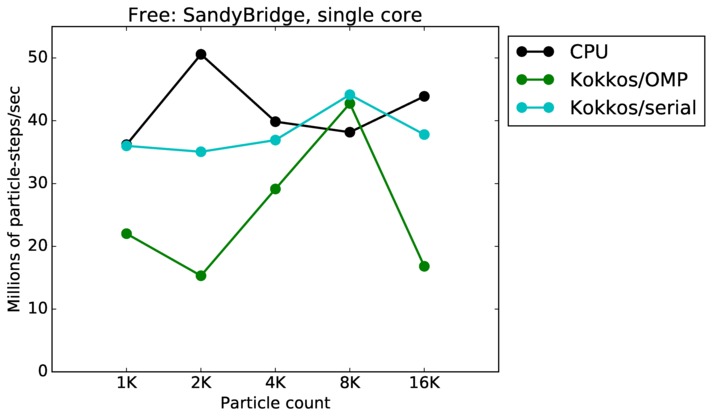
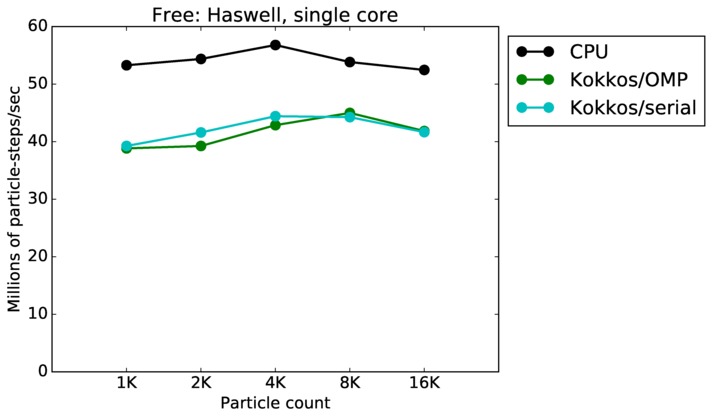
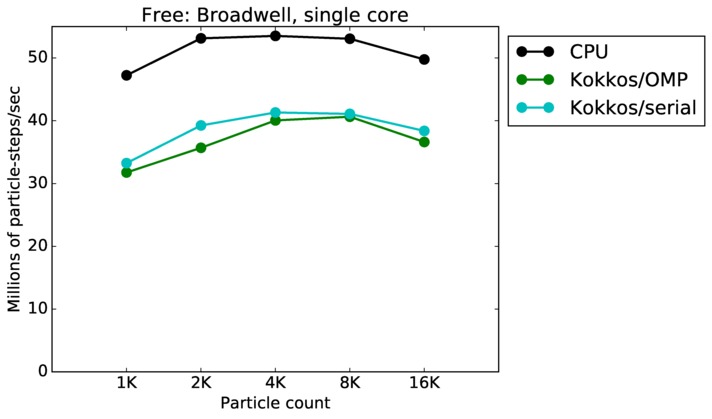
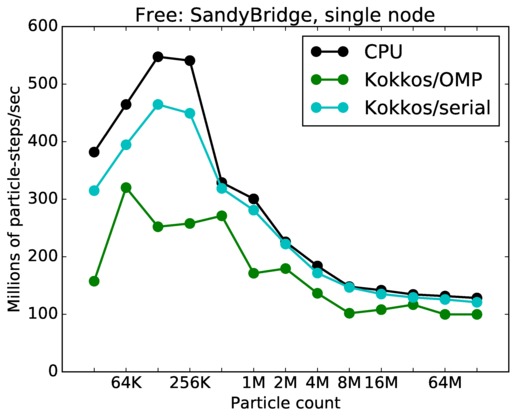
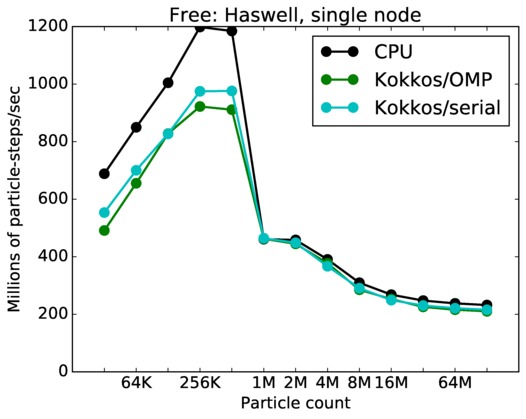
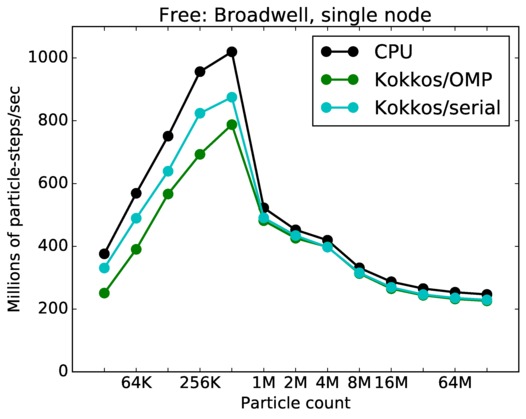
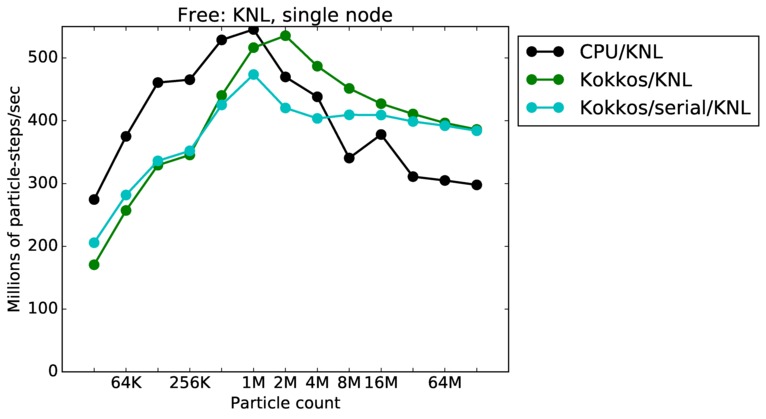
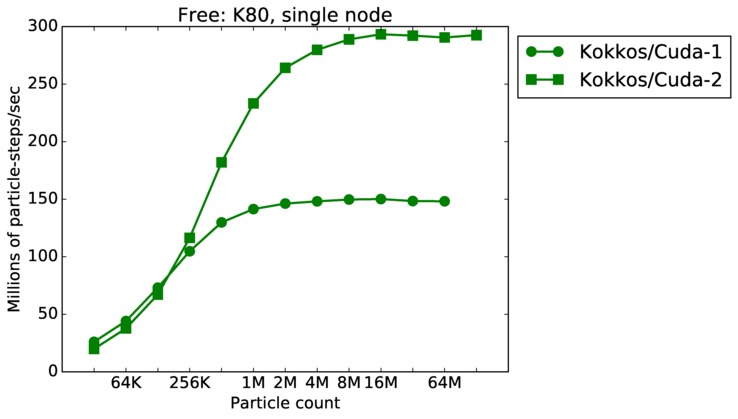
Free single core and single node performance:
Best timings for any accelerator option as a function of problem size. Running on a single CPU or KNL core. Running on a single CPU or KNL node or a single GPU. Only for double precision.

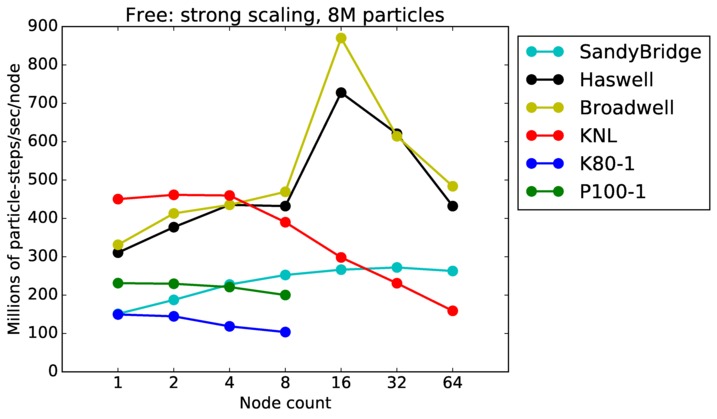
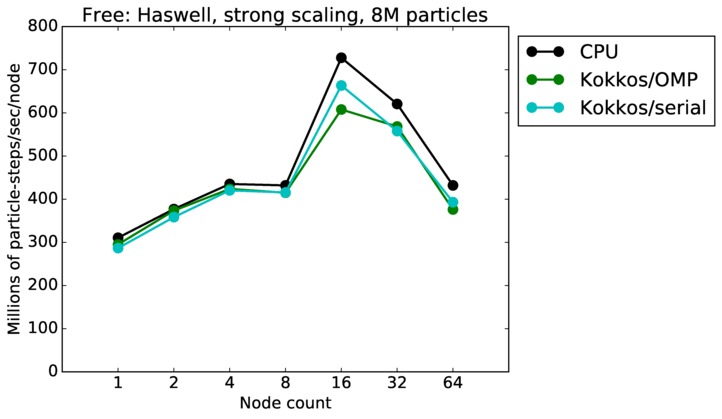
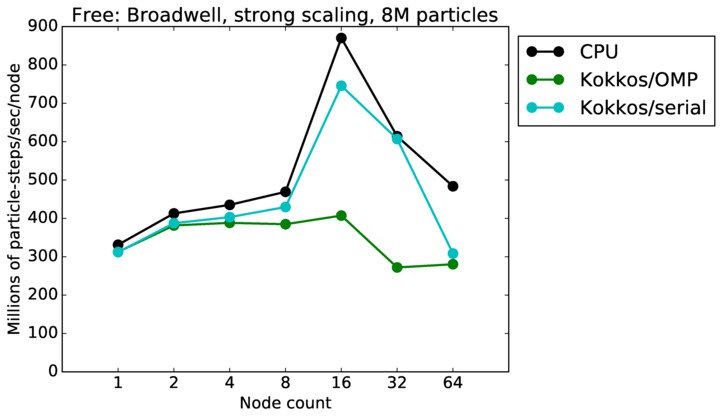
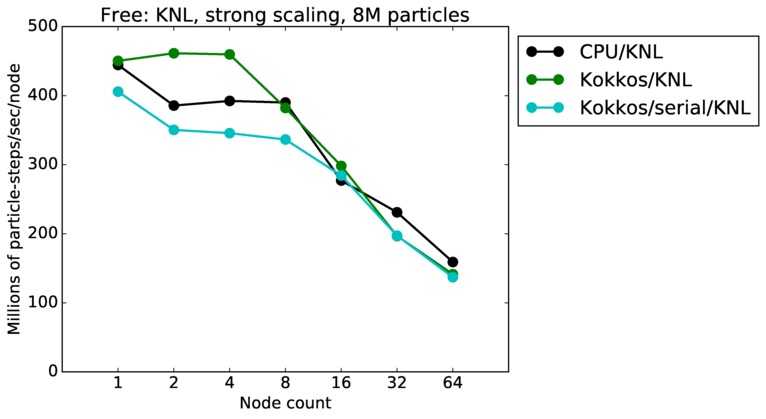
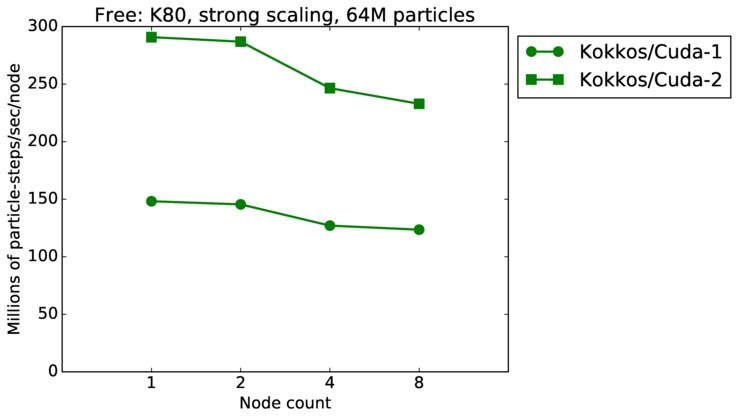
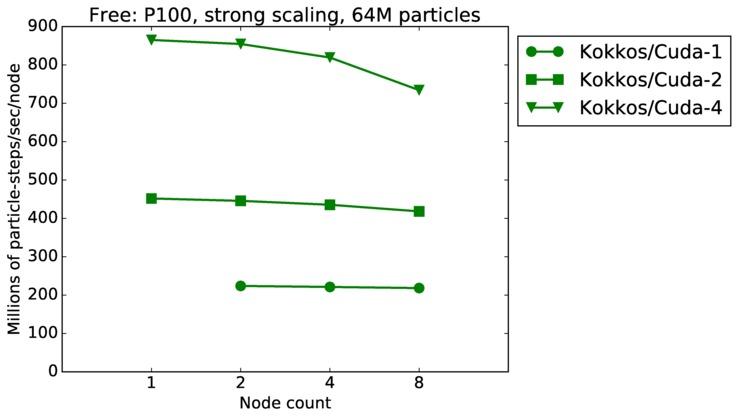
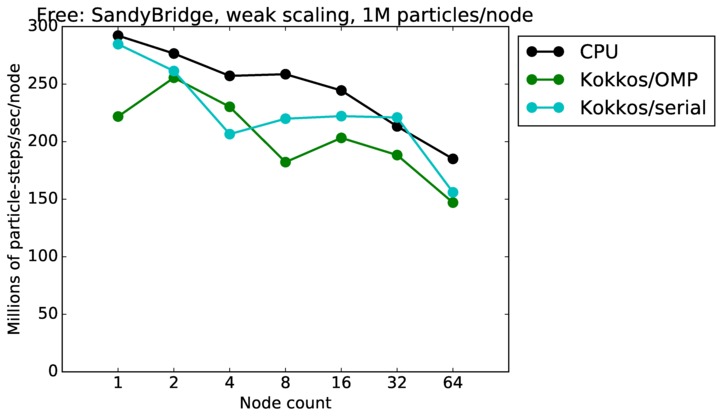
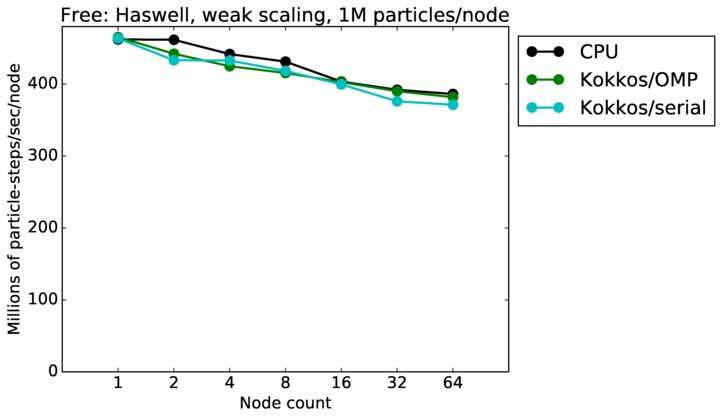
Free strong and weak scaling:
Fastest timing for any accelerator option running on multiple CPU or KNL or a single GPUs, as a function of node count. For strong scaling of 2 problem sizes: 8M particles, 64M particles. For weak scaling of 2 problem sizes: 1M particles/node, 16M particles/node. Only for a single GPU/node, only double precision.
Strong scaling means the same size problem is run on successively more nodes. Weak scaling means the problem size doubles each time the node count doubles. See a fuller description here of how to interpret these plots.
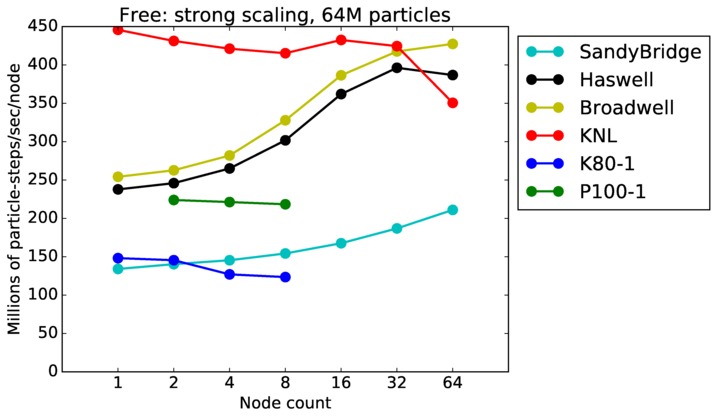
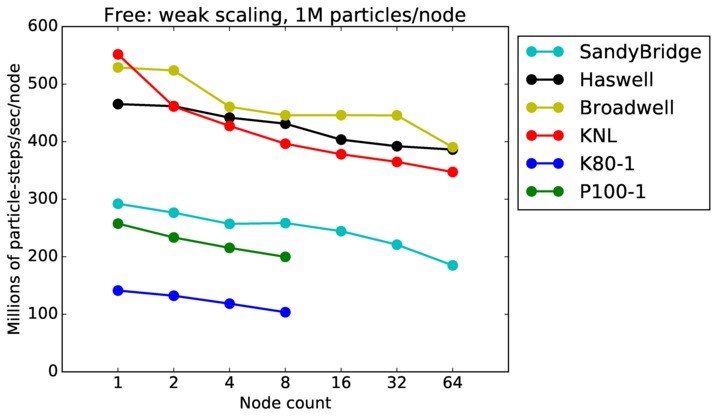
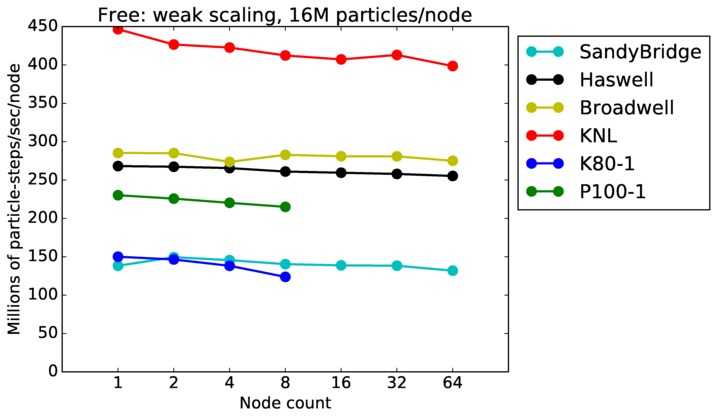
Free performance details:
| Mode | SPARTA Version | Hardware | Machine | Size | Plot | Table |
| core | 23Dec17 | SandyBridge | chama | 1K-16K | plot | table |
| core | 23Dec17 | Haswell | mutrino | 1K-16K | plot | table |
| core | 23Dec17 | Broadwell | serrano | 1K-16K | plot | table |
| core | 23Dec17 | KNL | mutrino | 1K-16K | plot | table |
| node | 23Dec17 | SandyBridge | chama | 32K-128M | plot | table |
| node | 23Dec17 | Haswell | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | Broadwell | serrano | 32K-128M | plot | table |
| node | 23Dec17 | KNL | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | K80 | ride80 | 32K-128M | plot | table |
| node | 23Dec17 | P100 | ride100 | 32K-128M | plot | table |
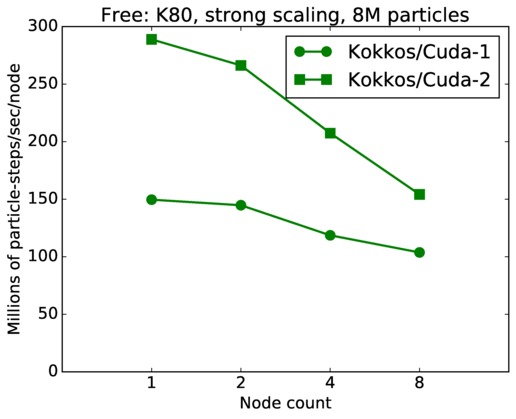
| strong | 23Dec17 | SandyBridge | chama | 8M | plot | table |
| strong | 23Dec17 | Haswell | mutrino | 8M | plot | table |
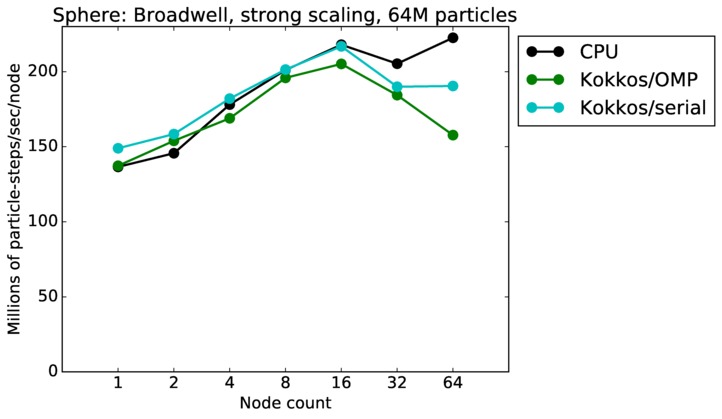
| strong | 23Dec17 | Broadwell | serrano | 8M | plot | table |
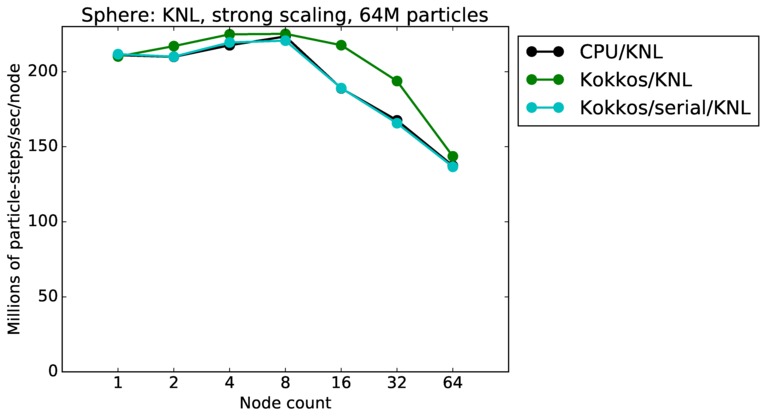
| strong | 23Dec17 | KNL | mutrino | 8M | plot | table |
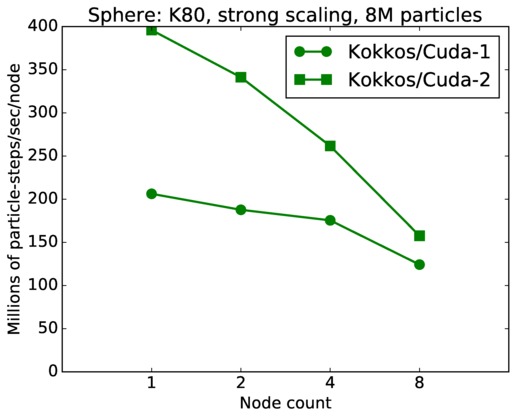
| strong | 23Dec17 | K80 | ride80 | 8M | plot | table |
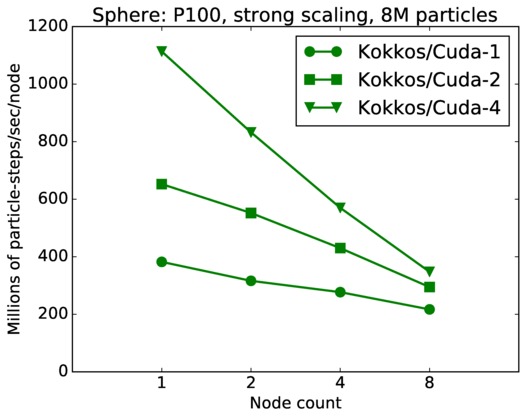
| strong | 23Dec17 | P100 | ride100 | 8M | plot | table |
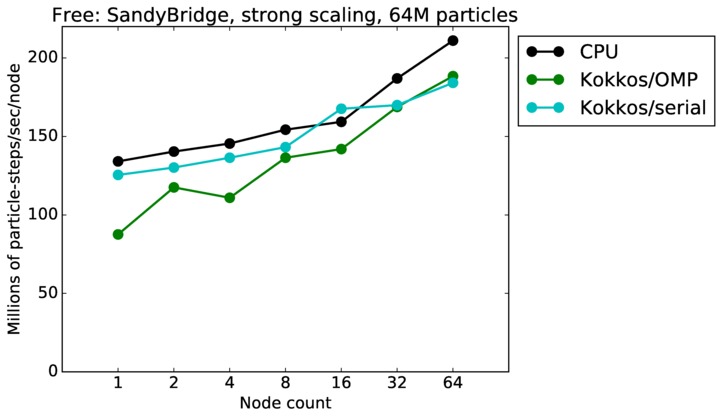
| strong | 23Dec17 | SandyBridge | chama | 64M | plot | table |
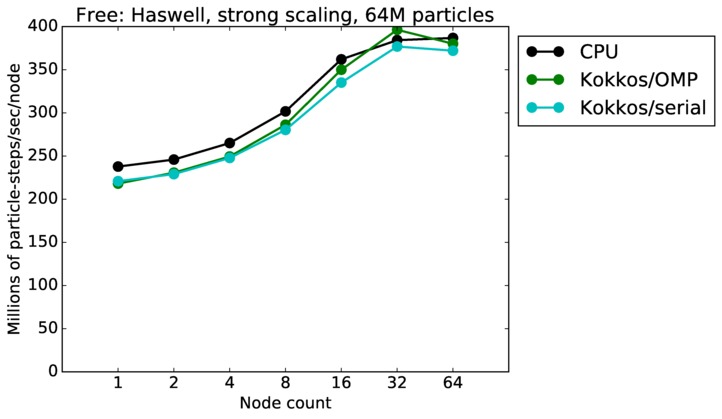
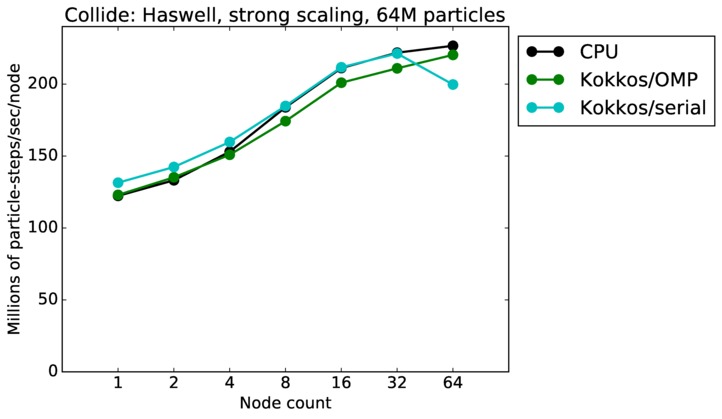
| strong | 23Dec17 | Haswell | mutrino | 64M | plot | table |
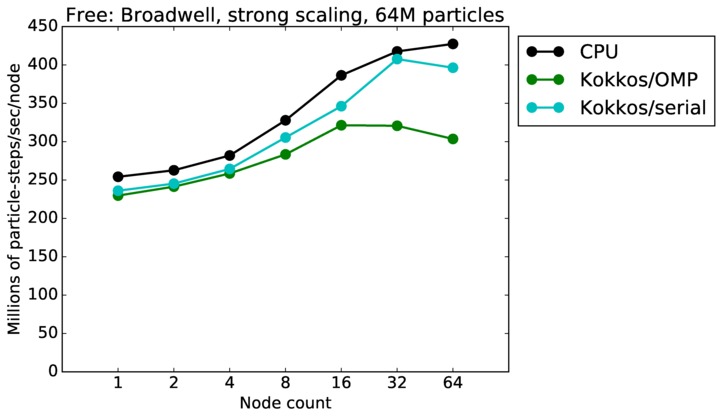
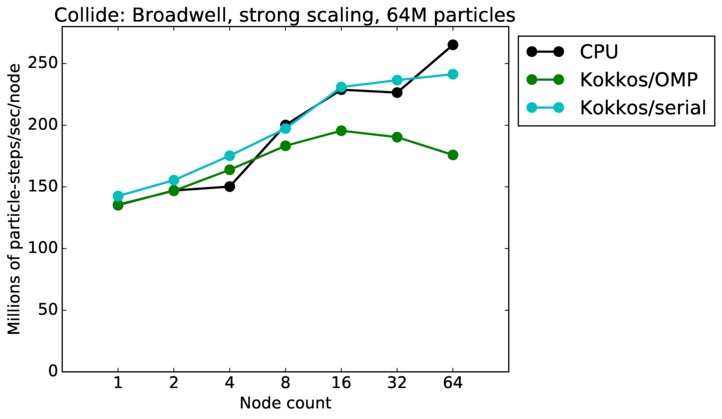
| strong | 23Dec17 | Broadwell | serrano | 64M | plot | table |
| strong | 23Dec17 | KNL | mutrino | 64M | plot | table |
| strong | 23Dec17 | K80 | ride80 | 64M | plot | table |
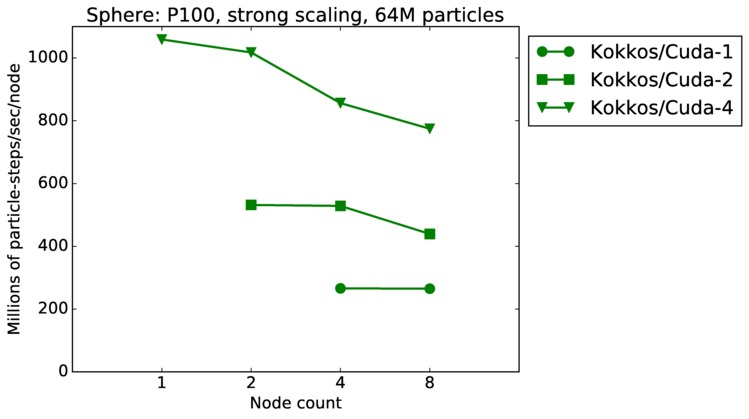
| strong | 23Dec17 | P100 | ride100 | 64M | plot | table |
| weak | 23Dec17 | SandyBridge | chama | 1M/node | plot | table |
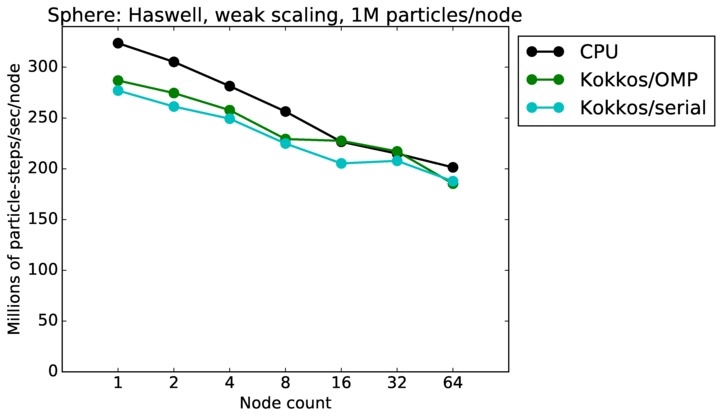
| weak | 23Dec17 | Haswell | mutrino | 1M/node | plot | table |
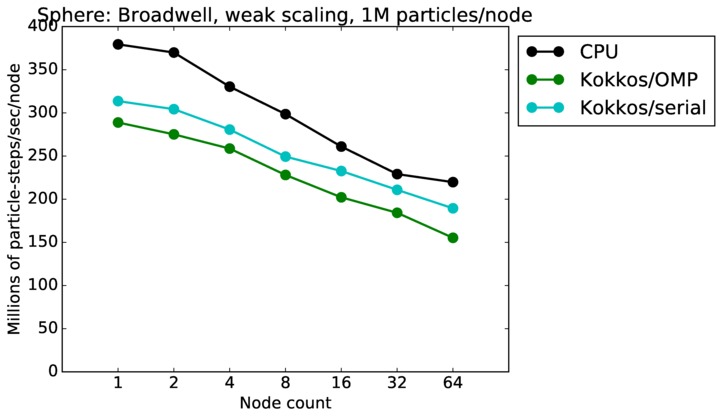
| weak | 23Dec17 | Broadwell | serrano | 1M/node | plot | table |
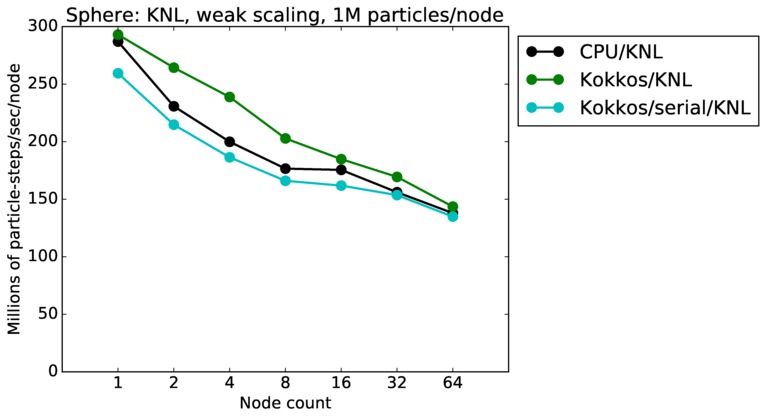
| weak | 23Dec17 | KNL | mutrino | 1M/node | plot | table |
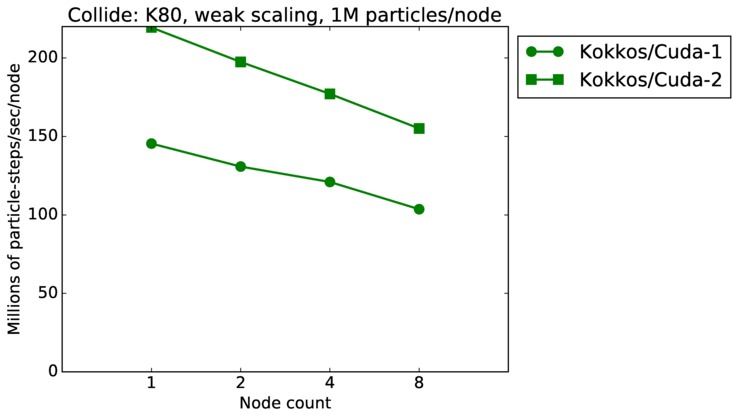
| weak | 23Dec17 | K80 | ride80 | 1M/node | plot | table |
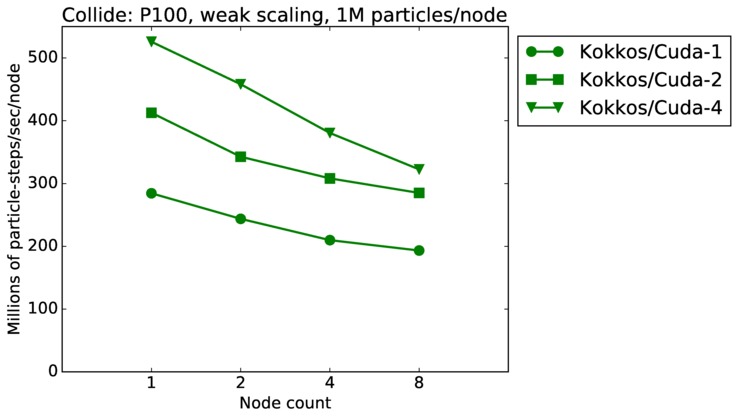
| weak | 23Dec17 | P100 | ride100 | 1M/node | plot | table |
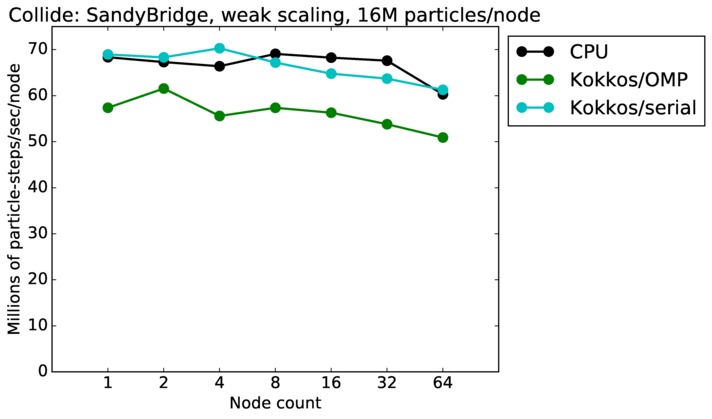
| weak | 23Dec17 | SandyBridge | chama | 16M/node | plot | table |
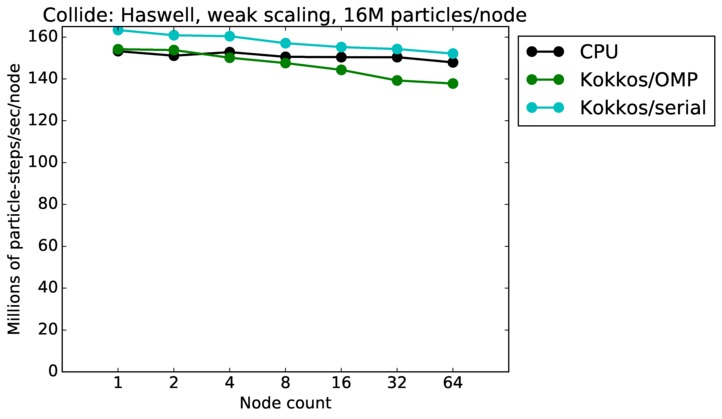
| weak | 23Dec17 | Haswell | mutrino | 16M/node | plot | table |
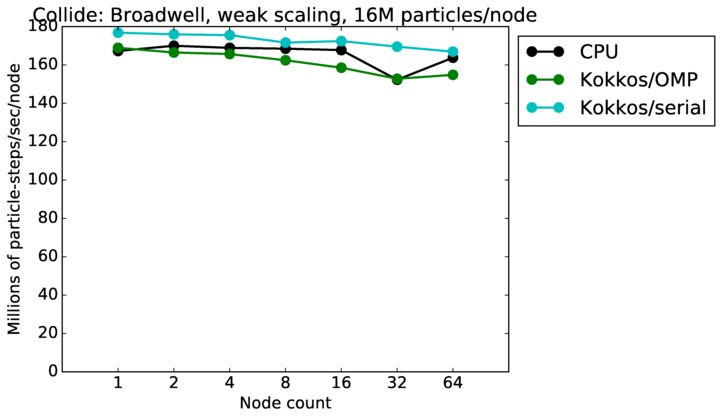
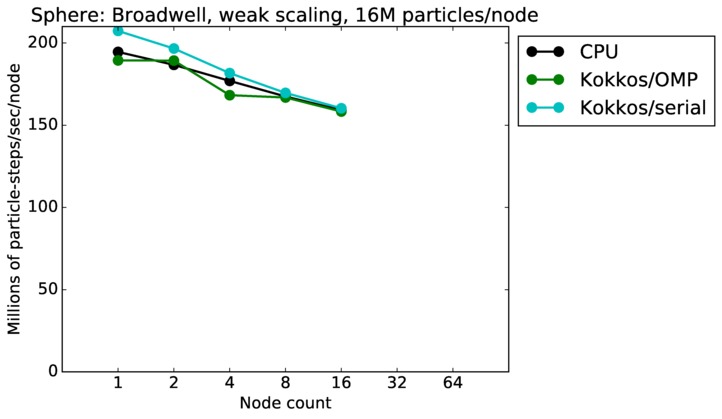
| weak | 23Dec17 | Broadwell | serrano | 16M/node | plot | table |
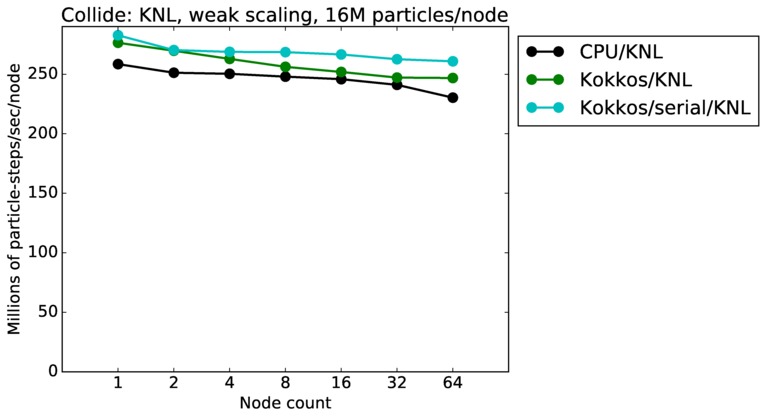
| weak | 23Dec17 | KNL | mutrino | 16M/node | plot | table |
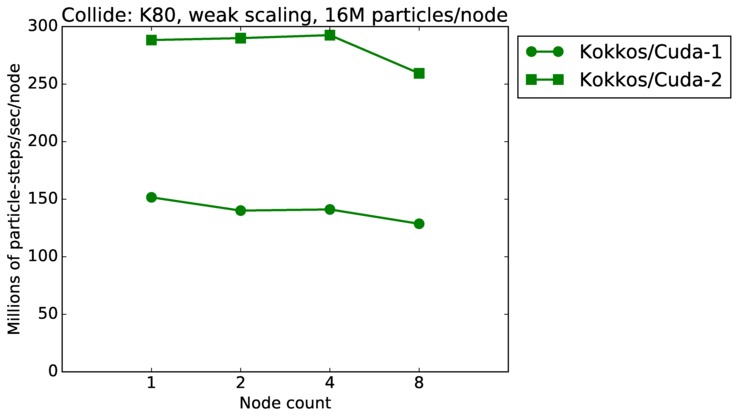
| weak | 23Dec17 | K80 | ride80 | 16M/node | plot | table |
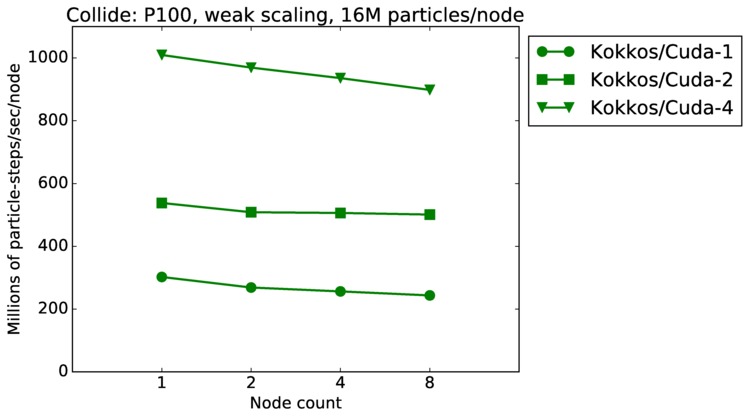
| weak | 23Dec17 | P100 | ride100 | 16M/node | plot | table |
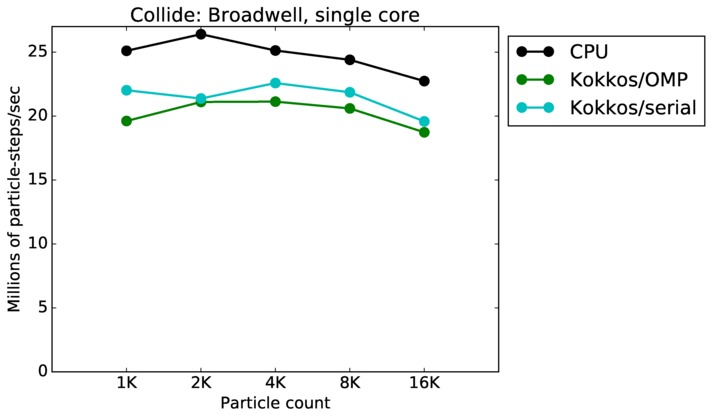
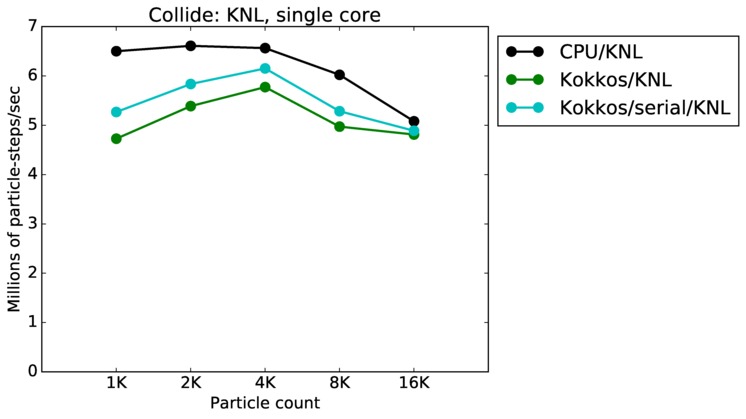
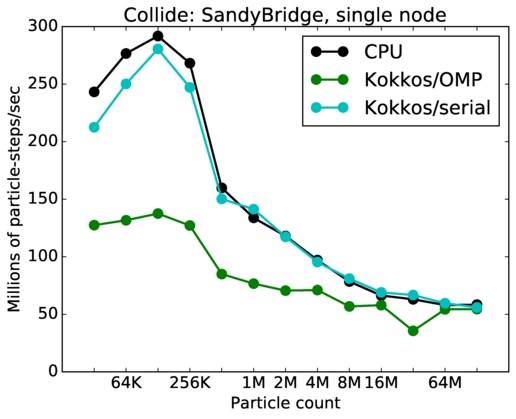
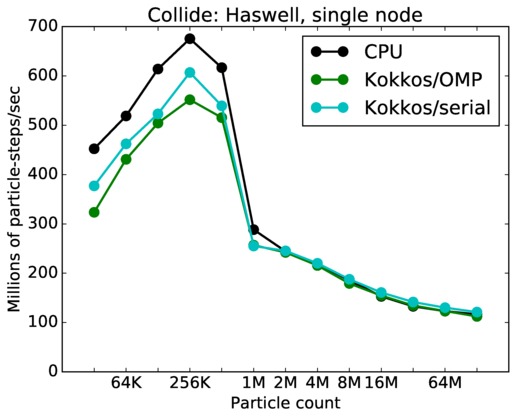
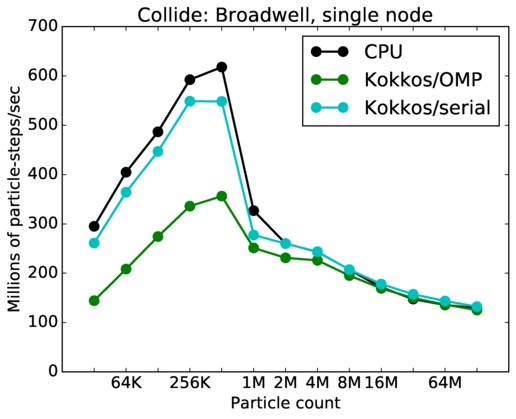
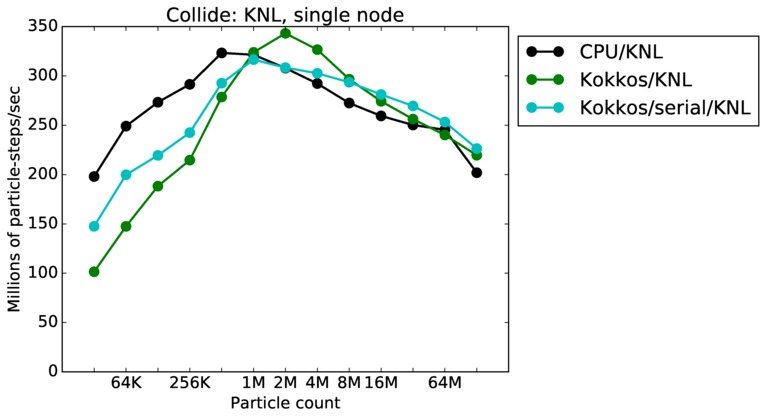
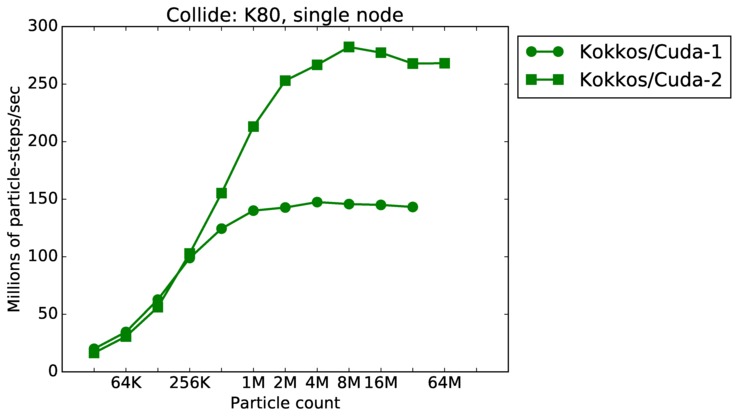
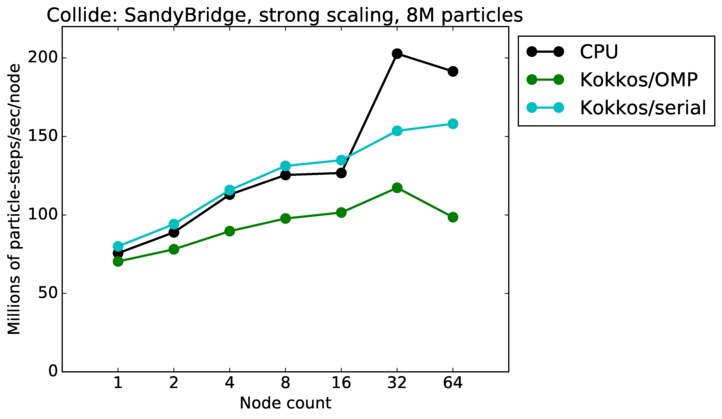
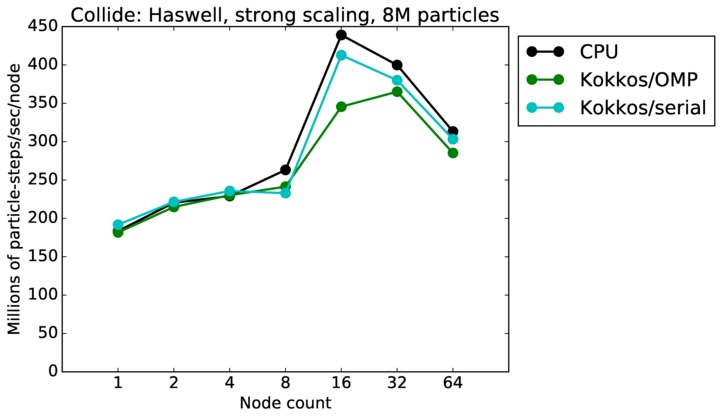
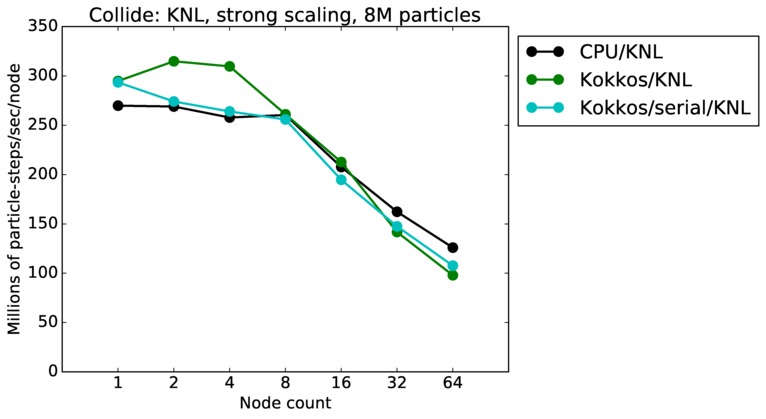
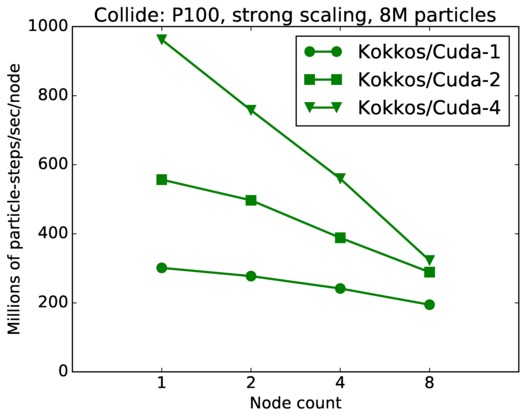
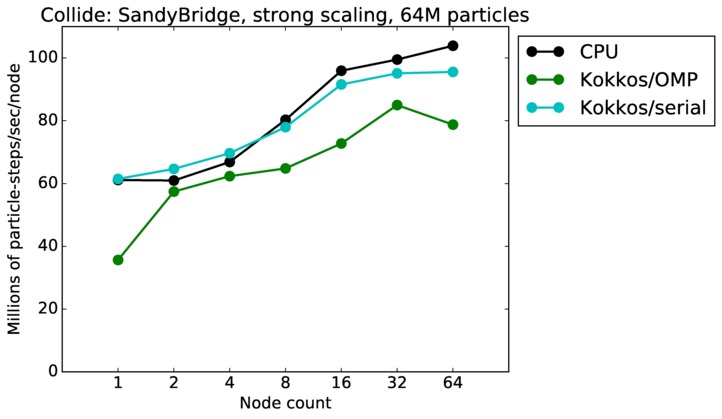
As described above, this benchmark is for particles undergoing collisional flow. Everything about the problem is the same as the free molecular flow problem described above, except that collisions were enabled, which requires extra computation, as well as particle sorting each timestep to identify particles in the same grid cell.
Additional packages needed for this benchmark: none
Comments:
Collide single core and single node performance:
Best timings for any accelerator option as a function of problem size. Running on a single CPU or KNL core. Running on a single CPU or KNL or a single GPU. Only for double precision.


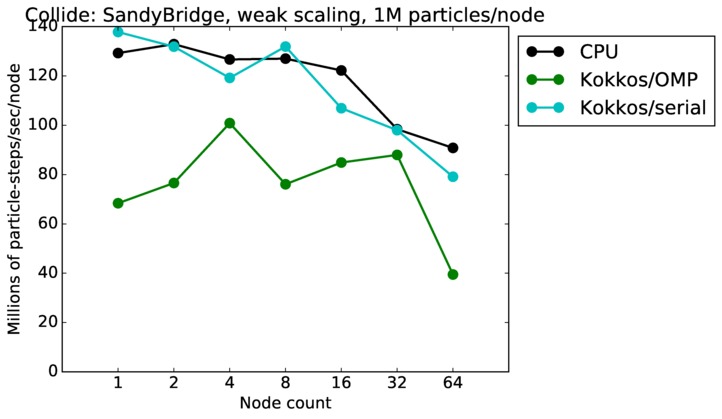
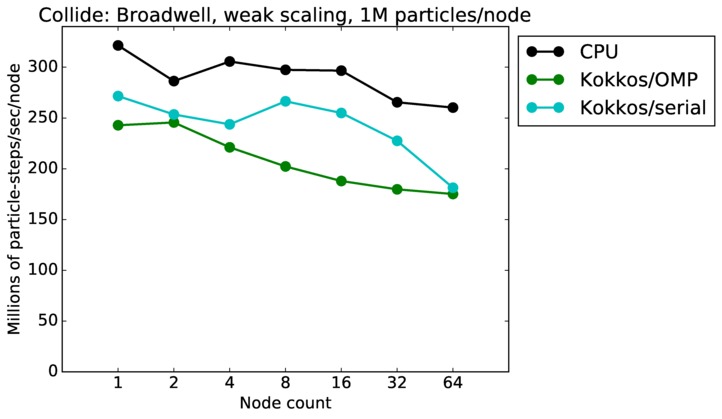
Collide strong and weak scaling:
Fastest timing for any accelerator option running on multiple CPU or KNL or a single GPUs, as a function of node count. For strong scaling of 2 problem sizes: 8M particles, 64M particles. For weak scaling of 2 problem sizes: 1M particles/node, 16M particles/node. Only for a single GPU/node, only double precision.
Strong scaling means the same size problem is run on successively more nodes. Weak scaling means the problem size doubles each time the node count doubles. See a fuller description here of how to interpret these plots.
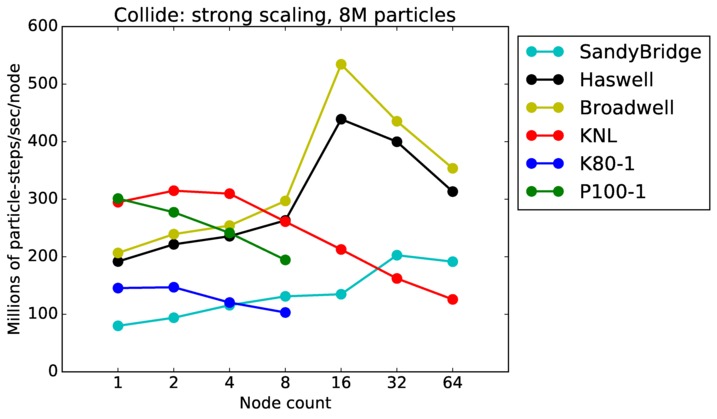
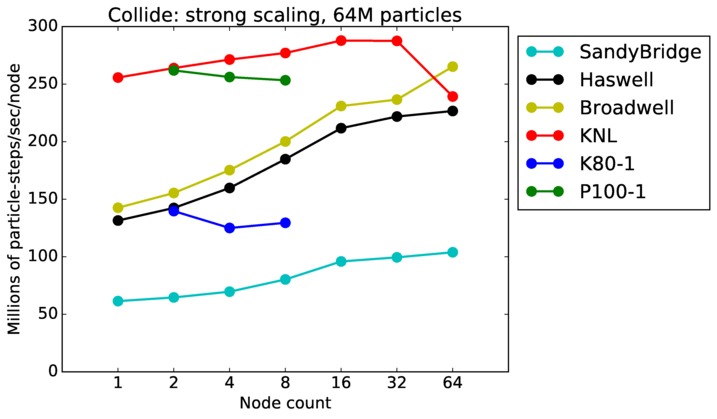
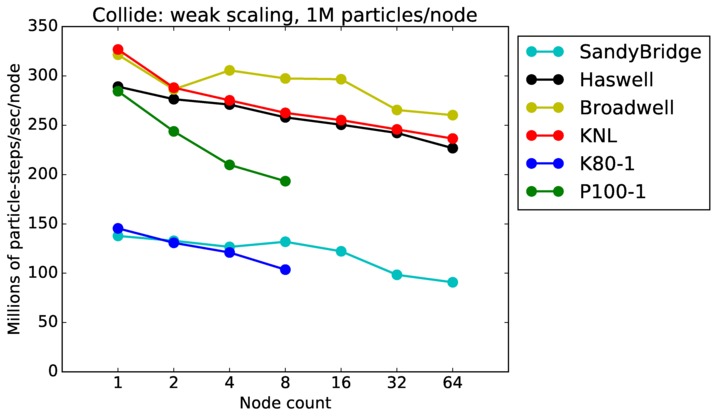
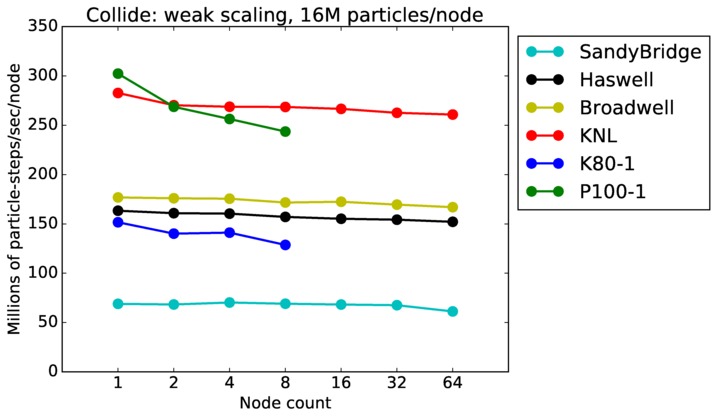
Collide performance details:
| Mode | SPARTA Version | Hardware | Machine | Size | Plot | Table |
| core | 23Dec17 | SandyBridge | chama | 1K-16K | plot | table |
| core | 23Dec17 | Haswell | mutrino | 1K-16K | plot | table |
| core | 23Dec17 | Broadwell | serrano | 1K-16K | plot | table |
| core | 23Dec17 | KNL | mutrino | 1K-16K | plot | table |
| node | 23Dec17 | SandyBridge | chama | 32K-128M | plot | table |
| node | 23Dec17 | Haswell | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | Broadwell | serrano | 32K-128M | plot | table |
| node | 23Dec17 | KNL | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | K80 | ride80 | 32K-128M | plot | table |
| node | 23Dec17 | P100 | ride100 | 32K-128M | plot | table |
| strong | 23Dec17 | SandyBridge | chama | 8M | plot | table |
| strong | 23Dec17 | Haswell | mutrino | 8M | plot | table |
| strong | 23Dec17 | Broadwell | serrano | 8M | plot | table |
| strong | 23Dec17 | KNL | mutrino | 8M | plot | table |
| strong | 23Dec17 | K80 | ride80 | 8M | plot | table |
| strong | 23Dec17 | P100 | ride100 | 8M | plot | table |
| strong | 23Dec17 | SandyBridge | chama | 64M | plot | table |
| strong | 23Dec17 | Haswell | mutrino | 64M | plot | table |
| strong | 23Dec17 | Broadwell | serrano | 64M | plot | table |
| strong | 23Dec17 | KNL | mutrino | 64M | plot | table |
| strong | 23Dec17 | K80 | ride80 | 64M | plot | table |
| strong | 23Dec17 | P100 | ride100 | 64M | plot | table |
| weak | 23Dec17 | SandyBridge | chama | 1M/node | plot | table |
| weak | 23Dec17 | Haswell | mutrino | 1M/node | plot | table |
| weak | 23Dec17 | Broadwell | serrano | 1M/node | plot | table |
| weak | 23Dec17 | KNL | mutrino | 1M/node | plot | table |
| weak | 23Dec17 | K80 | ride80 | 1M/node | plot | table |
| weak | 23Dec17 | P100 | ride100 | 1M/node | plot | table |
| weak | 23Dec17 | SandyBridge | chama | 16M/node | plot | table |
| weak | 23Dec17 | Haswell | mutrino | 16M/node | plot | table |
| weak | 23Dec17 | Broadwell | serrano | 16M/node | plot | table |
| weak | 23Dec17 | KNL | mutrino | 16M/node | plot | table |
| weak | 23Dec17 | K80 | ride80 | 16M/node | plot | table |
| weak | 23Dec17 | P100 | ride100 | 16M/node | plot | table |
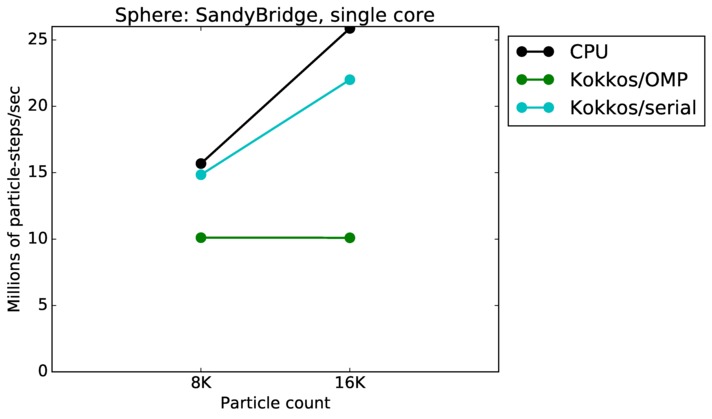
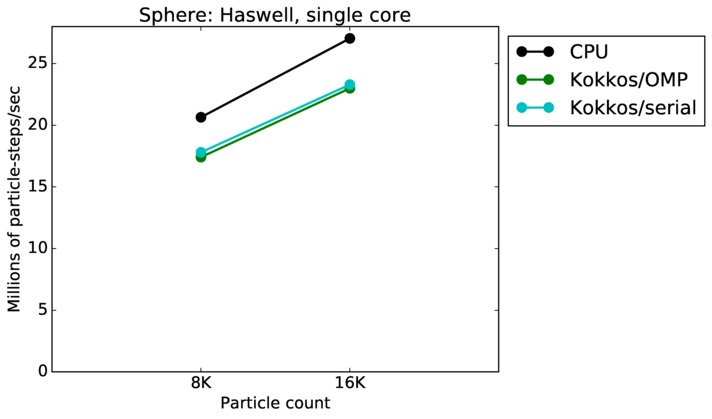
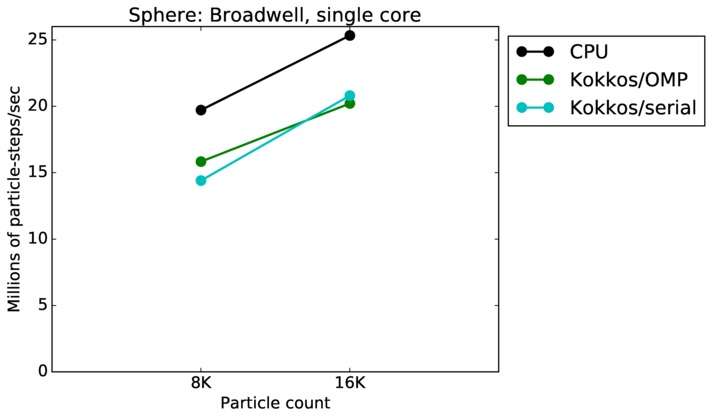
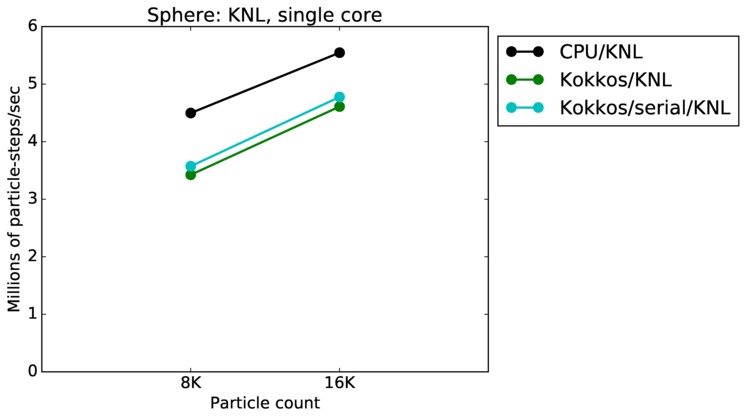
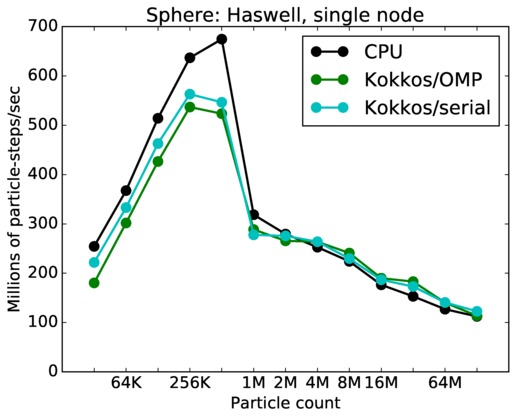
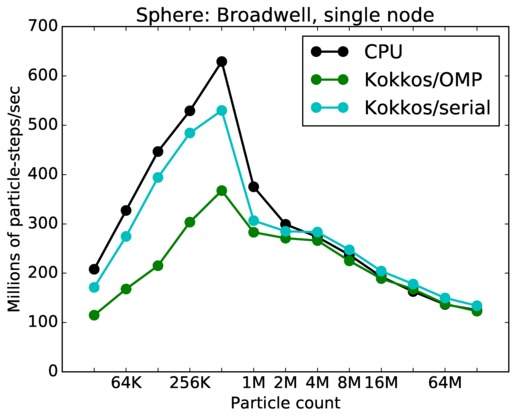
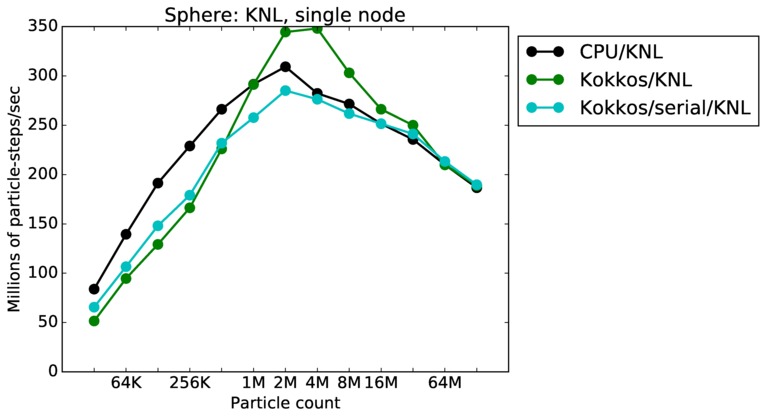
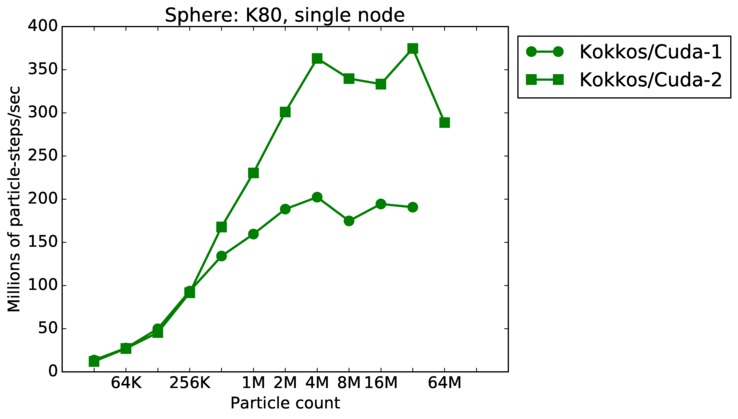
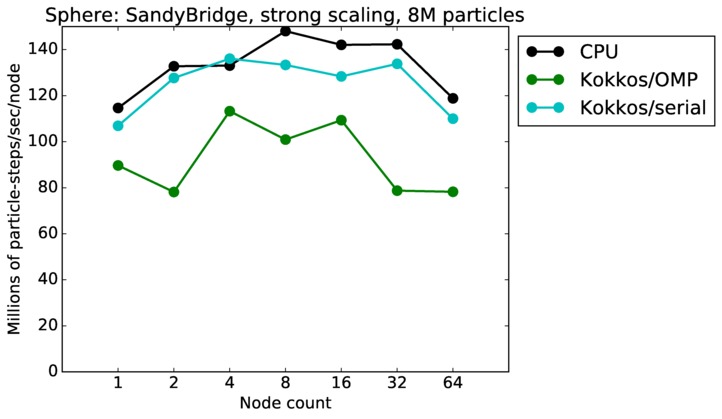
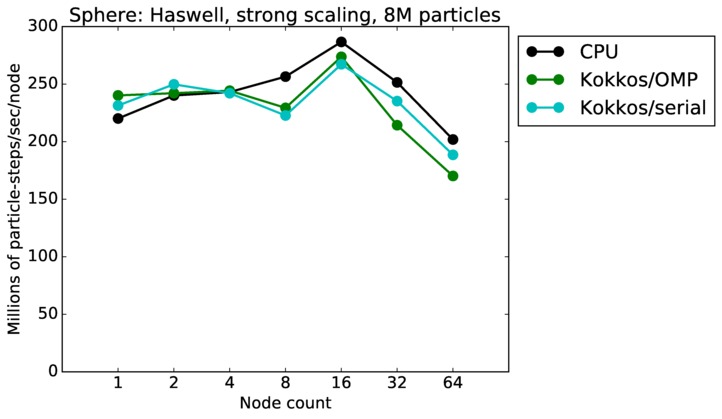
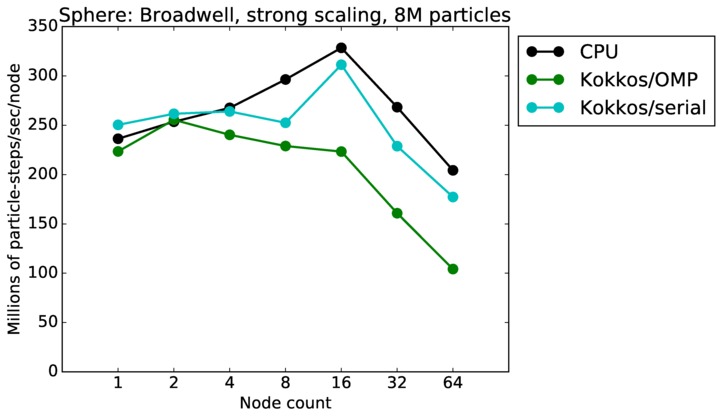
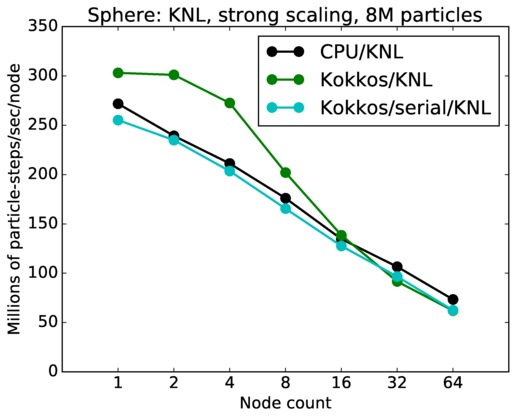
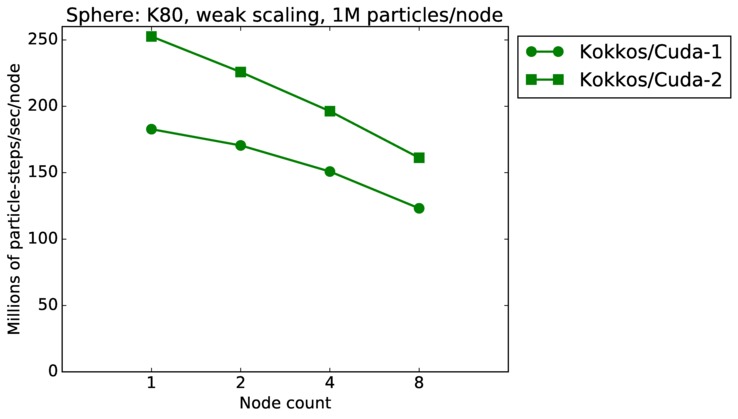
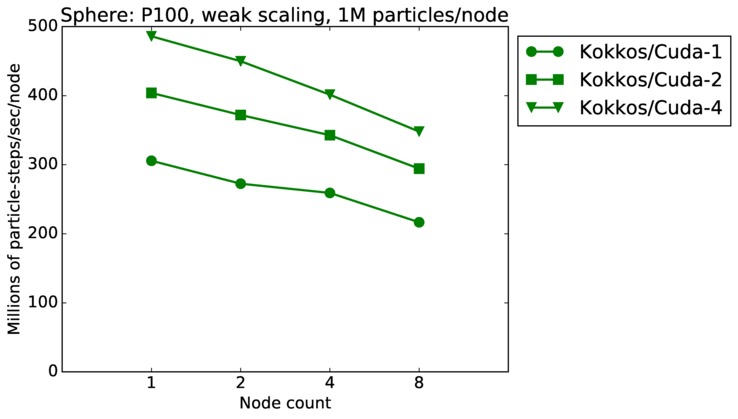
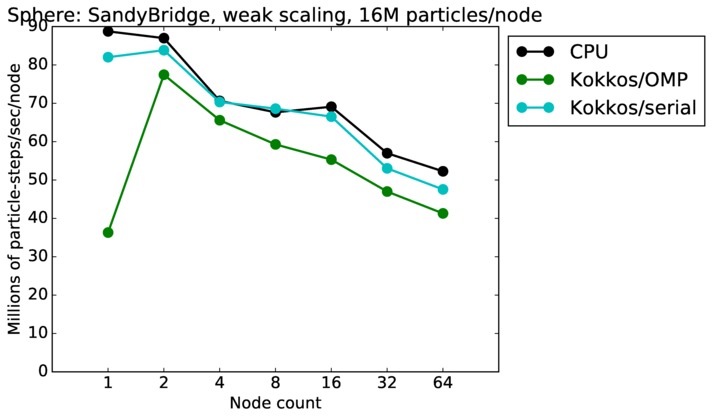
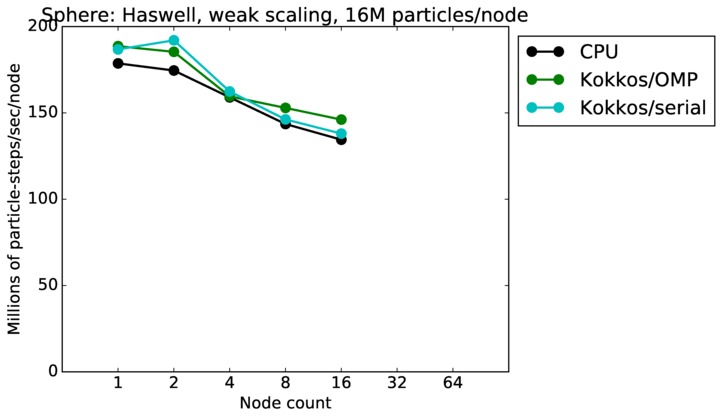
This benchmark is for particles flowing around a sphere.
Comments:
Sphere single core and single node performance:
Best timings for any accelerator option as a function of problem size. Running on a single CPU or KNL core. Running on a single CPU or KNL node or a single GPU. Only for double precision.
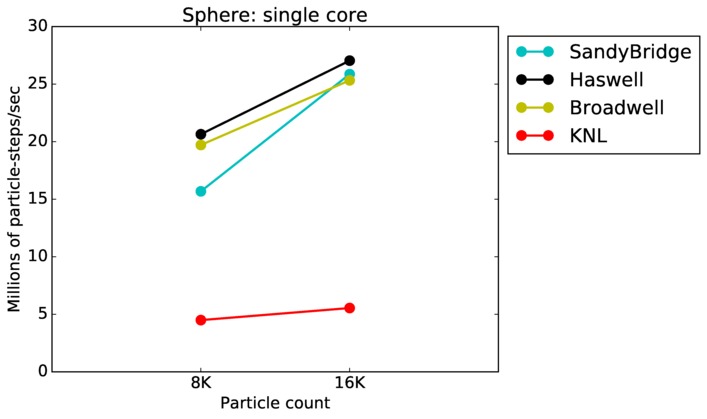
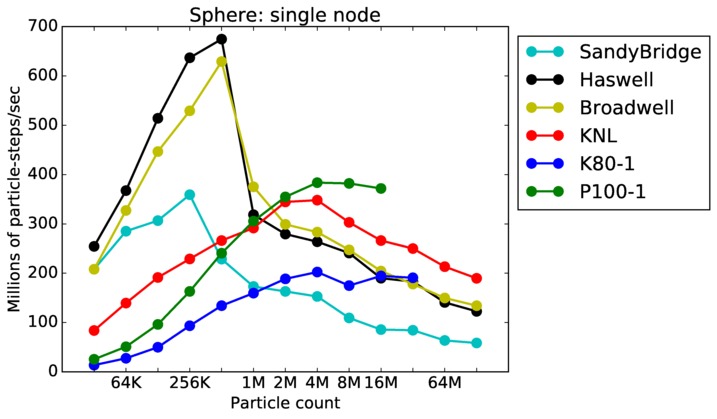
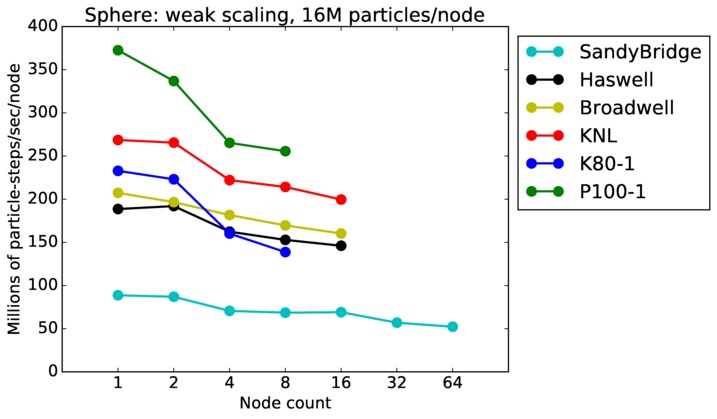
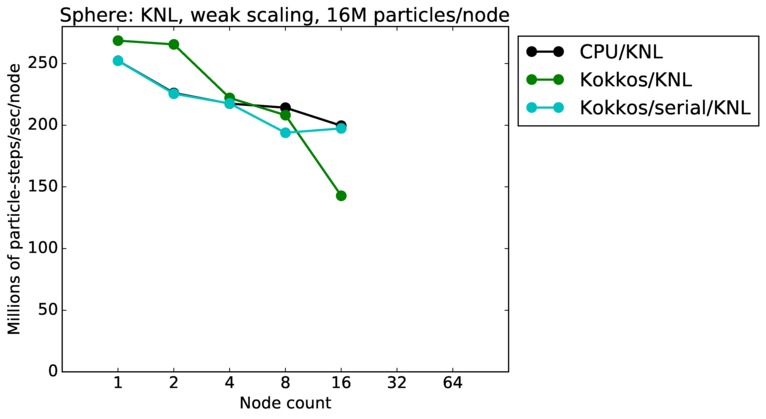
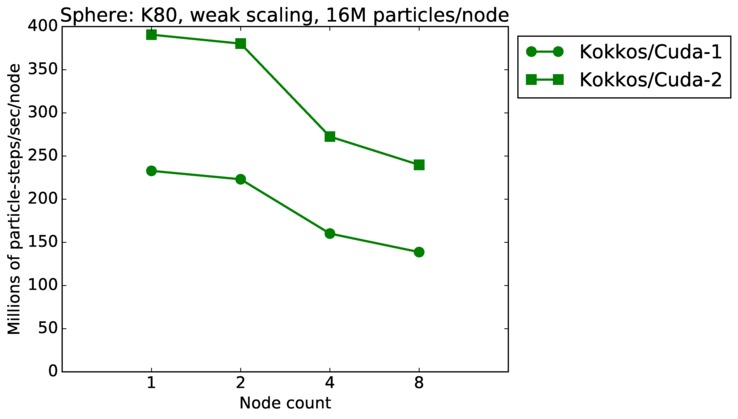
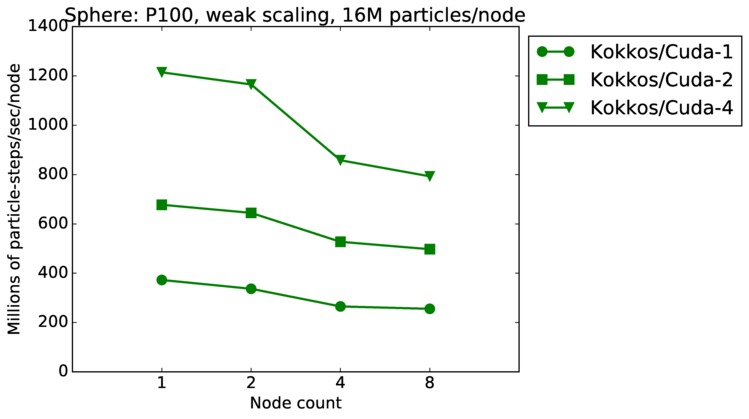
Sphere strong and weak scaling:
Fastest timing for any accelerator option running on multiple CPU or KNL or a single GPUs, as a function of node count. For strong scaling of 2 problem sizes: 8M particles, 64M particles. For weak scaling of 2 problem sizes: 1M particles/node, 16M particles/node. Only for a single GPU/node, only double precision.
Strong scaling means the same size problem is run on successively more nodes. Weak scaling means the problem size doubles each time the node count doubles. See a fuller description here of how to interpret these plots.
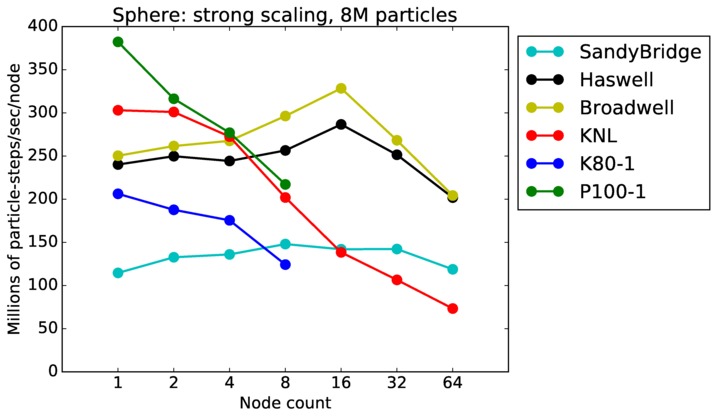
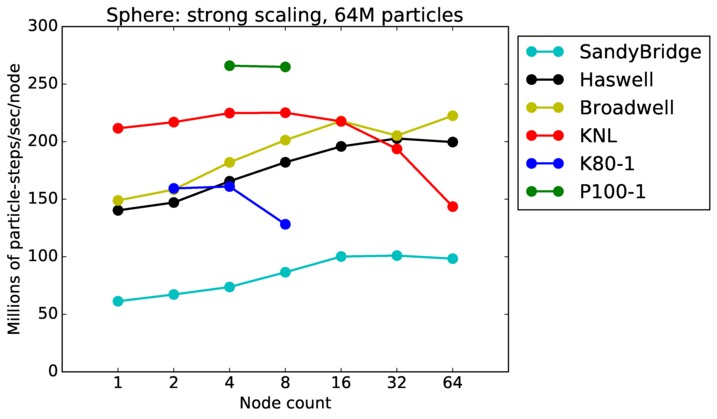
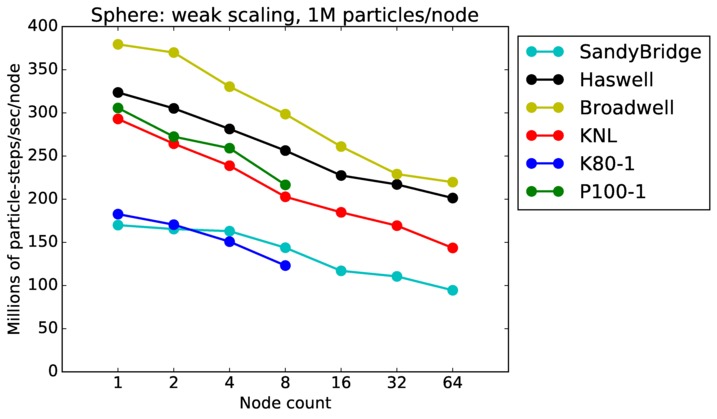
Sphere performance details:
| Mode | SPARTA Version | Hardware | Machine | Size | Plot | Table |
| core | 23Dec17 | SandyBridge | chama | 8K-16K | plot | table |
| core | 23Dec17 | Haswell | mutrino | 8K-16K | plot | table |
| core | 23Dec17 | Broadwell | serrano | 8K-16K | plot | table |
| core | 23Dec17 | KNL | mutrino | 8K-16K | plot | table |
| node | 23Dec17 | SandyBridge | chama | 32K-128M | plot | table |
| node | 23Dec17 | Haswell | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | Broadwell | serrano | 32K-128M | plot | table |
| node | 23Dec17 | KNL | mutrino | 32K-128M | plot | table |
| node | 23Dec17 | K80 | ride80 | 32K-128M | plot | table |
| node | 23Dec17 | P100 | ride100 | 32K-128M | plot | table |
| strong | 23Dec17 | SandyBridge | chama | 8M | plot | table |
| strong | 23Dec17 | Haswell | mutrino | 8M | plot | table |
| strong | 23Dec17 | Broadwell | serrano | 8M | plot | table |
| strong | 23Dec17 | KNL | mutrino | 8M | plot | table |
| strong | 23Dec17 | K80 | ride80 | 8M | plot | table |
| strong | 23Dec17 | P100 | ride100 | 8M | plot | table |
| strong | 23Dec17 | SandyBridge | chama | 64M | plot | table |
| strong | 23Dec17 | Haswell | mutrino | 64M | plot | table |
| strong | 23Dec17 | Broadwell | serrano | 64M | plot | table |
| strong | 23Dec17 | KNL | mutrino | 64M | plot | table |
| strong | 23Dec17 | K80 | ride80 | 64M | plot | table |
| strong | 23Dec17 | P100 | ride100 | 64M | plot | table |
| weak | 23Dec17 | SandyBridge | chama | 1M/node | plot | table |
| weak | 23Dec17 | Haswell | mutrino | 1M/node | plot | table |
| weak | 23Dec17 | Broadwell | serrano | 1M/node | plot | table |
| weak | 23Dec17 | KNL | mutrino | 1M/node | plot | table |
| weak | 23Dec17 | K80 | ride80 | 1M/node | plot | table |
| weak | 23Dec17 | P100 | ride100 | 1M/node | plot | table |
| weak | 23Dec17 | SandyBridge | chama | 16M/node | plot | table |
| weak | 23Dec17 | Haswell | mutrino | 16M/node | plot | table |
| weak | 23Dec17 | Broadwell | serrano | 16M/node | plot | table |
| weak | 23Dec17 | KNL | mutrino | 16M/node | plot | table |
| weak | 23Dec17 | K80 | ride80 | 16M/node | plot | table |
| weak | 23Dec17 | P100 | ride100 | 16M/node | plot | table |
SPARTA has an accelerator option implemented via the KOKKOS package, accelerator packages. The KOKKOS packages support multiple hardware options.
For acceleration on a CPU:
For acceleration on an Intel KNL:
For acceleration on an NVIDIA GPU:
Benchmarks were run on the following machines and node hardware.
chama = Intel SandyBridge CPUs
mutrino = Intel Haswell CPUs or Intel KNLs
serrano = Intel Broadwell CPUs
ride80 = IBM Power8 CPUs with NVIDIA K80 GPUs
ride100 = IBM Power8 CPUs with NVIDIA P100 GPUs
This table shows which accelerator packages were used on which machines:
| Machine | Hardware | CPU | Kokkos/OMP | Kokkos/KNL | Kokkos/Cuda |
| chama | SandyBridge | yes | yes | no | no |
| mutrino | Haswell/KNL | yes | yes | yes | no |
| serrano | Broadwell | yes | yes | no | no |
| ride80 | K80 | no | no | no | yes |
| ride100 | P100 | no | no | no | yes |
These are the software environments on each machine and the Makefiles used to build SPARTA with different accelerator packages.
chama
mutrino
serrano
ride80
ride100
If a specific benchmark requires a build with additional package(s) installed, it is noted with the benchmark info below.
With the software environment initialized (e.g. modules loaded) and the machine Makefiles copied into src/MAKE/MINE, building SPARTA is straightforward:
cp Makefile.serrano_kokkos_omp sparta/src/MAKE/MINE # for example cd sparta/src make yes-kokkos # install accelerator package(s) supported by the Makefile make serrano_kokkos_omp # target = suffix of Makefile.machine
This should produce an executable named spa_machine, e.g. spa_serrano_kokkos_omp. If desired, you can copy the executable to a directory where you run the benchmark.
IMPORTANT NOTE: Achieving best performance for the benchmarks (or your own input script) on a particular machine with a particular accelerator option, requires attention to the following issues.
All of the plots below include a link to a table with details on all of these issues. The table shows the mpirun (or equivalent) command used to produce each data point on each curve in the plot, the SPARTA command-line arguments used to get best performance with a particular package on that hardware, and a link to the logfile produced by the benchmark run.
All the plots below have particles or nodes on the x-axis, and performance on the y-axis. On all the plots, better performance is up and worse performance is down. For all the plots:
Per-core and per-node plots:
Strong-scaling and weak-scaling plots:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}